Lexical Processing

There are 3 steps in the Mining Process:
- Text Pre-Processing
- Inputs: unstructured data, Text, Html
- Model Building
1. Text Pre-Processing:
- Text encoding(ASCII, Unicode, etc)
- Converting to lowercase
- Removing Symbols and punctuations
- Handling numbers
- Stop-Word removal
- Tokenization
- Stemming and Lemmatisation
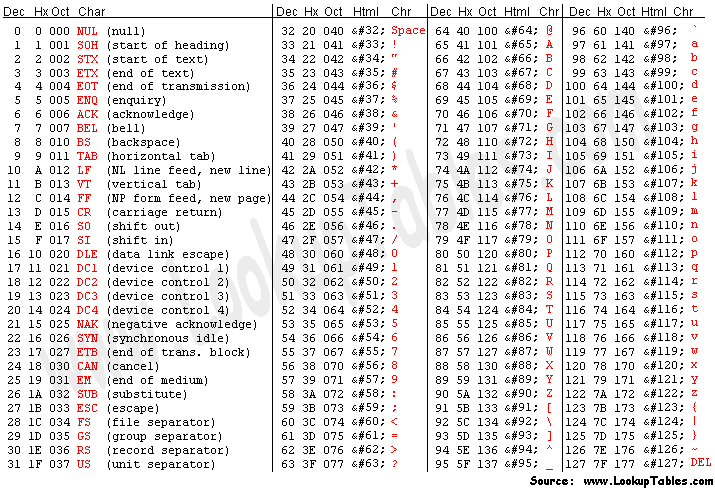
1.1 Text Encoding:
Computers understand Numerical Degrees so we can use binary. So encoding the alphabet and symbols to bits i.e. US-ASCII -> 0-127 decimal values assigned to symbols
The group of 8 bits but not include 128-255
ex: in Python, you can check unicode by ord(x)= 120 and character by chr(120) = 'x'. You can check the AsciiTable For more details.
for script:
for i in range(0,127):
ch = chr(i)
print(str(i) + " == '" +ch +"'")
Common Text Encoders:
- input Alphabet --> ASCII --> output binary 8bit
- Input Characters & --> Utf-8 --> output binary 8bit
- Input Characters & --> Utf-16 --> output binary 16bit
# create a string
amount = u"$"
print('Default string: ', amount, '\n', 'Type', type(amount), '\n')
# encode UTF-8 ->byte format
amount_encoded = amount.encode('utf-8')
print('Encoded to UTF-8: ', amount_encoded, 'Type', type(amount_encoded), '\n')
# decode UTF-8 <-byte format
amount_decoded = amount_encoded.decode('utf-8')
print('Decoded UTF-8: ', amount_decoded, '\n', 'Type', type(amount_decoded), '\n')
1.2 Converting text to Lowercase, Removing Symbols and punctuations & Handling numbers:
These three are some kind of text standardized to make text pre-process and give standardized input.
Handling Numbers is still tricky as we may need or may not need when texts are more important in such cases and also in some cases we need both(Keep Alphanumeric Tokens).
1.5 Stop-Word Removal
There are three kinds of words:
- Highly frequent words called stop words, such as “is,” “an,” and “the”
- Significant words, which are typically more important than the other words to understand the text
- Rarely occurring words, which are less important than significant words
There are 2 reasons to remove:
- They don't give much weight to info.
- The frequency is too high to reduce the data size and also reduce the feature size.


Comments
Post a Comment